We introduce FoleyGenEx, a unified framework for video-to-audio (VTA) generation that integrates multi-modal control, frame-level temporal alignment, and fine-grained semantic expressivity, enabling synchronized, versatile, and expressive audio synthesis across diverse tasks. Existing VTA methods either offer multi-modal control with weak temporal alignment or achieve strong alignment while lacking reference audio conditioning and semantic precision. FoleyGenEx bridges this gap through three key innovations: a conditional injection mechanism enabling audio-controlled VTA and Foley extension, a multi-modal dynamic masking strategy preserving synchronization during multi-modal training, and an adverb-based data augmentation algorithm leveraging signal processing and large language models to enrich audio representations and textual supervision with nuanced semantic cues. Experiments on AudioCaps, VGGSound, and Greatest Hits show that FoleyGenEx delivers competitive performance in controllable VTA generation, achieving strong temporal fidelity, versatile multi-modal control, and fine-grained semantic precision compared to existing methods.
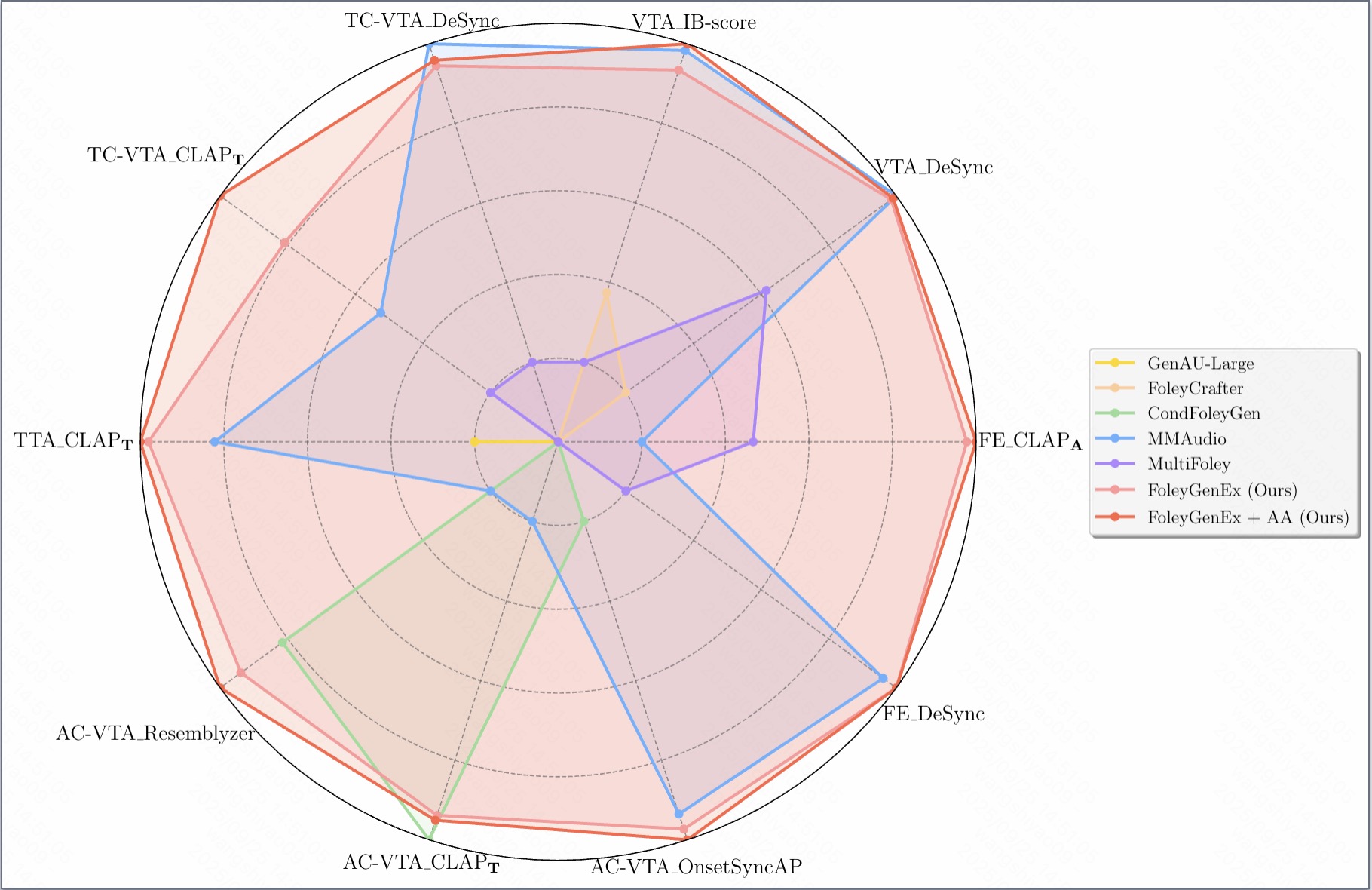
Figure 1: FoleyGenEx supports a range of multi-modal controlled audio generation tasks, including Text-to-Audio (TTA), basic Video-to-Audio (VTA), Text-Controlled VTA (TC-VTA), Audio-Controlled VTA (AC-VTA), and Foley extension (FE). It unifies these tasks while achieving strong synchronization, versatile control, and expressive audio generation.
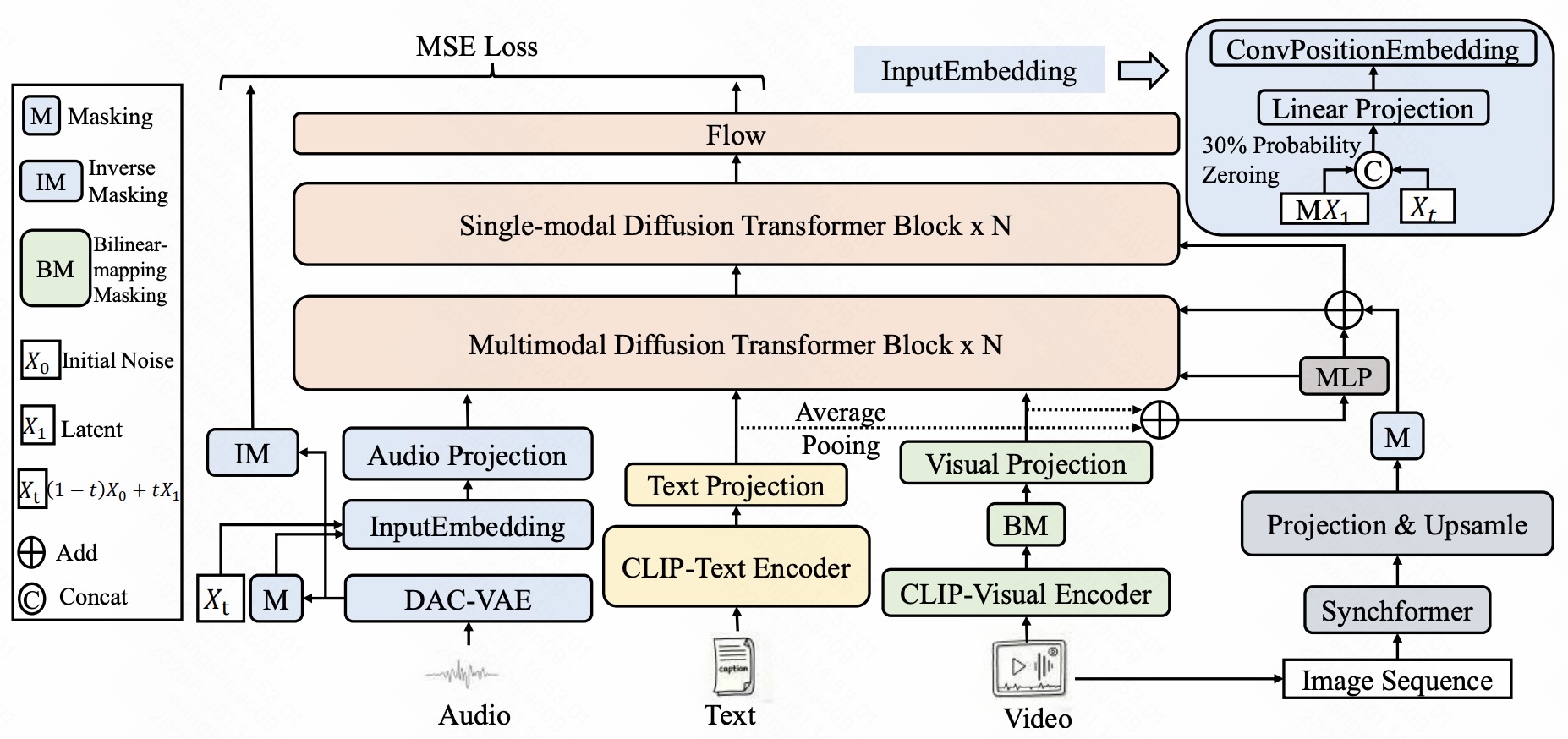
Figure 2: FoleyGenEx training framework.
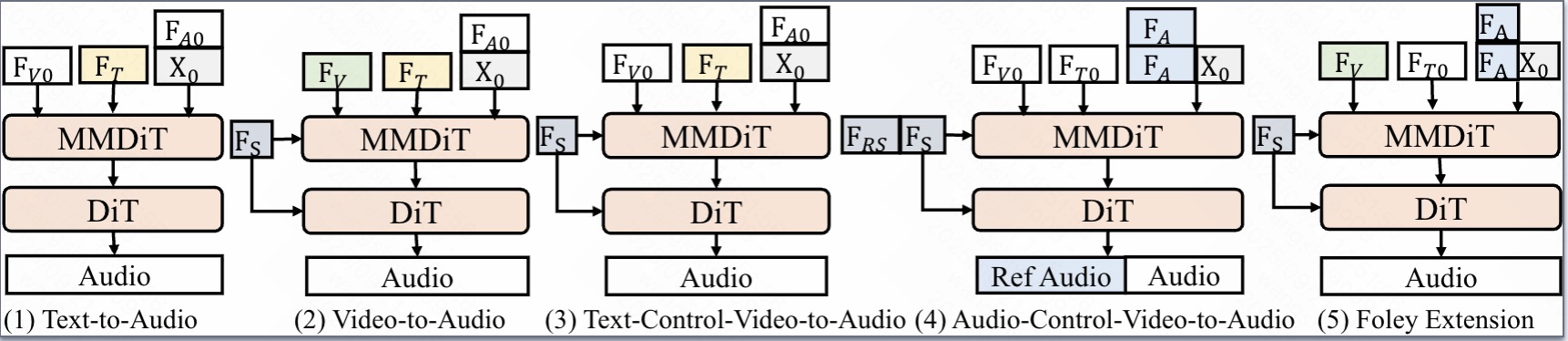
Figure 3: Multi-modal controlled audio generation tasks.
Bird chirping.
Male speaking.
Rooster crowing.
Sheep bleating.
Bird chirping.
Male speaking.
Rooster crowing.
Sheep bleating.
Cat meowing.
Horse neighing.
Lion roaring.
Cat meowing.
Horse neighing.
Lion roaring.
Typewriter.
Playing piano.
Typing on computer keyboard.
Typewriter.
Playing piano.
Typing on computer keyboard.
Playing cello.
Playing erhu.
Chainsawing trees.
Playing cello.
Playing erhu.
Chainsawing trees.
Cat meowing.
Tiger roaring.
Inference conditions: 2-second audio snippet from reference video & 2-second copied snippet from target video
Reference Audio
Result 1
Result 2
Reference Audio
Result 1
Result 2
Reference Audio
Result 1
Result 2
Reference Audio
Result 1
Result 2
Reference Audio
Result
Reference Audio
Result
Inference conditions: 2-second audio snippet from reference video & 2-second copied snippet from target video
Reference Audio
Result 1
Result 2
Reference Audio
Result 1
Result 2
Reference Audio
Result 1
Result 2
Input: Provides the first 5-second audio clip
Result
Input: Provides the first 5 - second audio clip
Result
Input: Provides the first 5 - second audio clip
Result
Input: Provides the first 5 - second audio clip
Result
Input: Provides the first 5 - second audio clip
Result
Input: Provides the first 5 - second audio clip
Result
Input: Provides the first 5 - second audio clip
Result
Input: Provides the first 5 - second audio clip
Result
Input: Provides the first 5 - second audio clip
Result
Edit the 0-3s segment and input the text as "pouring milk"
Result
Regenerate the 7.5-10s segment based on the 0-7.5s segment
Result
Regenerate the 2-5s segment based on the rest of the segments
Result
Regenerate the 0-1.5s segment based on the rest of the segments
Result
Regenerate the 0-2s segment based on the rest of the segments
Result
Regenerate the 0-2s segment based on the rest of the segments
Result
Regenerate the 0-5s segment based on the rest of the segments
Result
| Test Caption | MMAudio (w/o AA) | MMAudio (w/ AA) |
|---|---|---|
| A dog runs excitedly from a distance to nearby. | ||
| A commercial airliner flies farther away gradually. | ||
| Guests are chatting and laughing in the distance. | ||
| Ambient sounds of a remote village. | ||
| Heavy rain, and terrifying thunder rings out in a distant place. | ||
| In the distance along the road, an artist is playing a lively Swiss folk song. | ||
| A black cat lets out a soft meow. | ||
| A beautiful woman sits in front of the piano and plays rapidly. | ||
| The soft tapping sound of metal. | ||
| Rapid footsteps echo in the corridor. |